

Z.ai (formerly Zhipu) today announced GLM-4.5V, an open-source vision-language model engineered for robust multimodal reasoning across images, video, long documents, charts, and GUI screens.
Multimodal reasoning is widely viewed as a key pathway toward AGI. GLM-4.5V advances that agenda with a 100B-class architecture (106B total parameters, 12B active) that pairs high accuracy with practical latency and deployment cost. The release follows July’s GLM-4.1V-9B-Thinking, which hit #1 on Hugging Face Trending and has surpassed 130,000 downloads, and scales that recipe to enterprise workloads while keeping developer ergonomics front and center. The model is accessible through multiple channels, including Hugging Face [http://huggingface.co/zai-org/GLM-4.5V], GitHub [http://github.com/zai-org/GLM-V], Z.ai API Platform [http://docs.z.ai/guides/vlm/glm-4.5v], and Z.ai Chat [http://chat.z.ai], ensuring broad developer access.
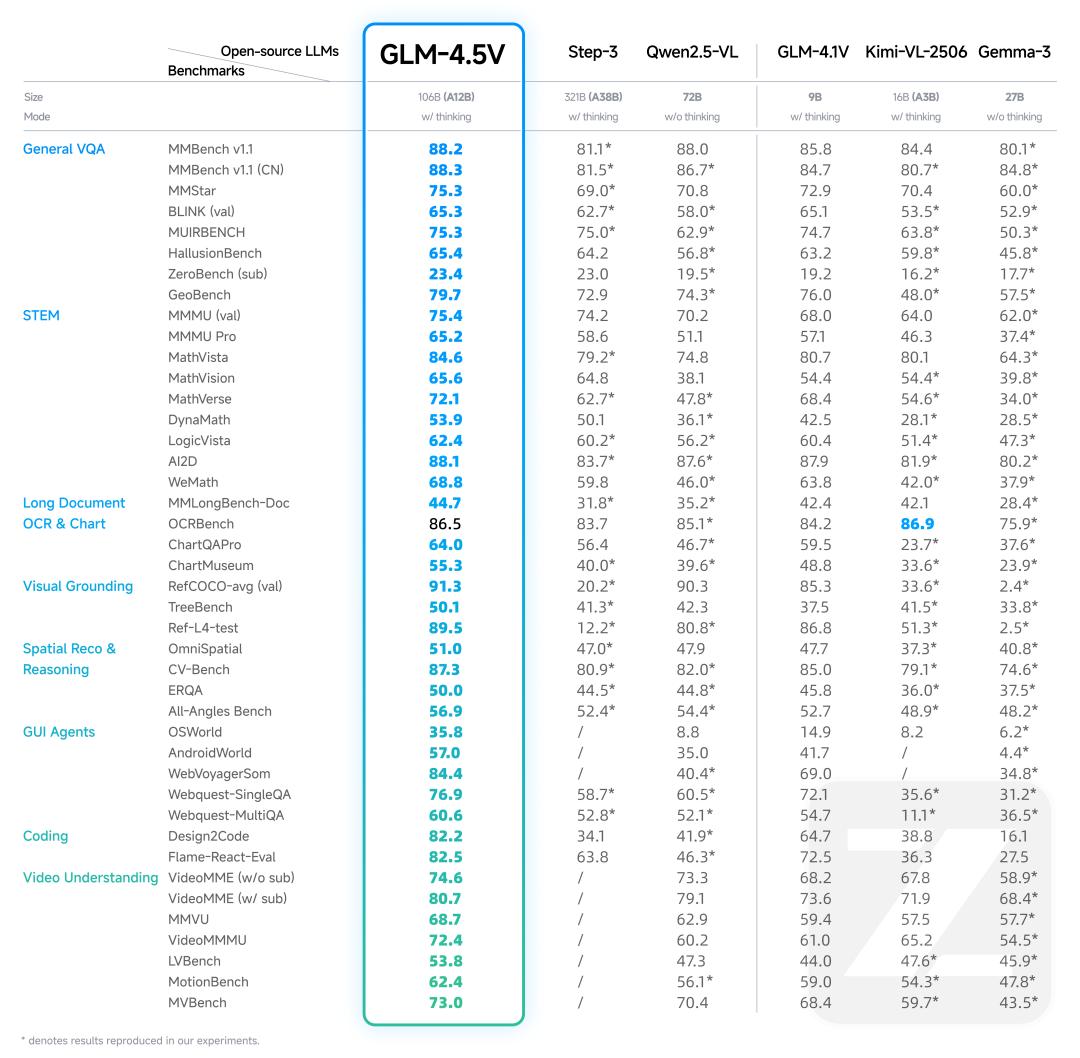
Open-Source SOTA
Built on the new GLM-4.5-Air text base and extending the GLM-4.1V-Thinking lineage, GLM-4.5V delivers SOTA performance among similarly sized open-source VLMs across 41 public multimodal evaluations. Beyond leaderboards, the model is engineered for real-world usability and reliability on noisy, high-resolution, and extreme-aspect-ratio inputs.
The result is all-scenario visual reasoning in practical pipelines: image reasoning (scene understanding, multi-image analysis, localization), video understanding (shot segmentation and event recognition), GUI tasks (screen reading, icon detection, desktop assistance), complex chart and long-document analysis (report understanding and information extraction), and precise grounding (accurate spatial localization of visual elements).
Image: https://www.globalnewslines.com/uploads/2025/08/1ca45a47819aaf6a111e702a896ee2bc.jpg
Key Capabilities
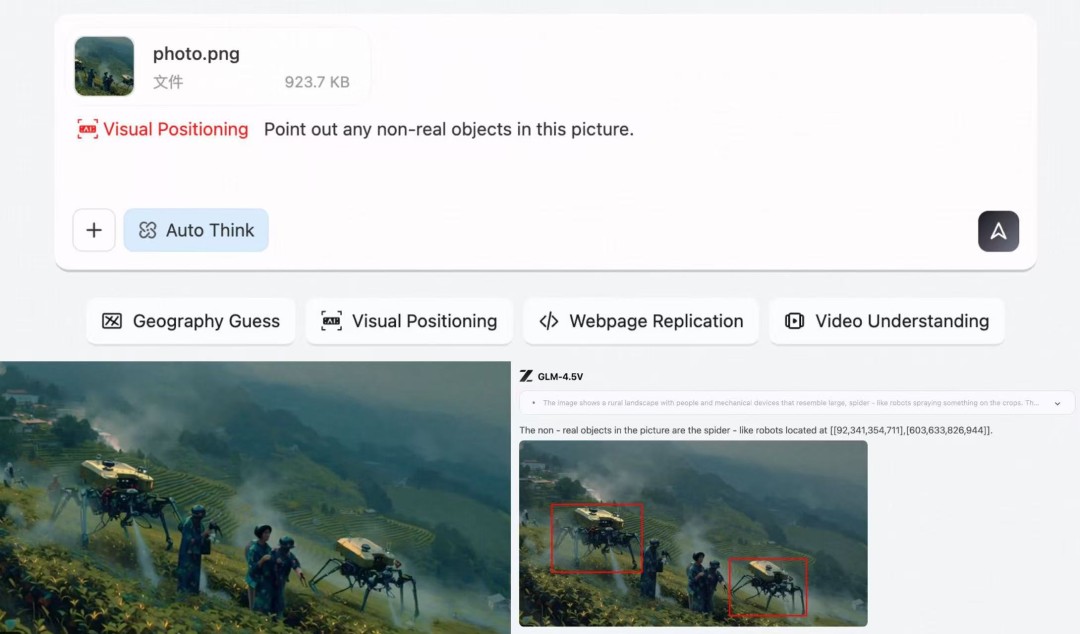
Visual grounding and localization
GLM-4.5V precisely identifies and locates target objects based on natural-language prompts and returns bounding coordinates. This enables high-value applications such as safety and quality inspection or aerial/remote-sensing analysis. Compared with conventional detectors, the model leverages broader world knowledge and stronger semantic reasoning to follow more complex localization instructions.
Users can switch to the Visual Positioning mode, upload an image and a short prompt, and get back the box and rationale. For example, ask “Point out any non-real objects in this picture.” GLM-4.5V reasons about plausibility and materials, then flags the insect-like sprinkler robot (the item highlighted in red in the demo) as non-real, returning a tight bounding box a confidence score, and a brief explanation.
Image: https://www.globalnewslines.com/uploads/2025/08/8dcbdd7939f12f7a2239bfbb0528b3f7.jpg
Design-to-code from screenshots and interaction videos
The model analyzes page screenshots-and even interaction videos-to infer hierarchy, layout rules, styles, and intent, then emits faithful, runnable HTML/CSS/JavaScript. Beyond element detection, it reconstructs the underlying logic and supports region-level edit requests, enabling an iterative loop between visual input and production-ready code.
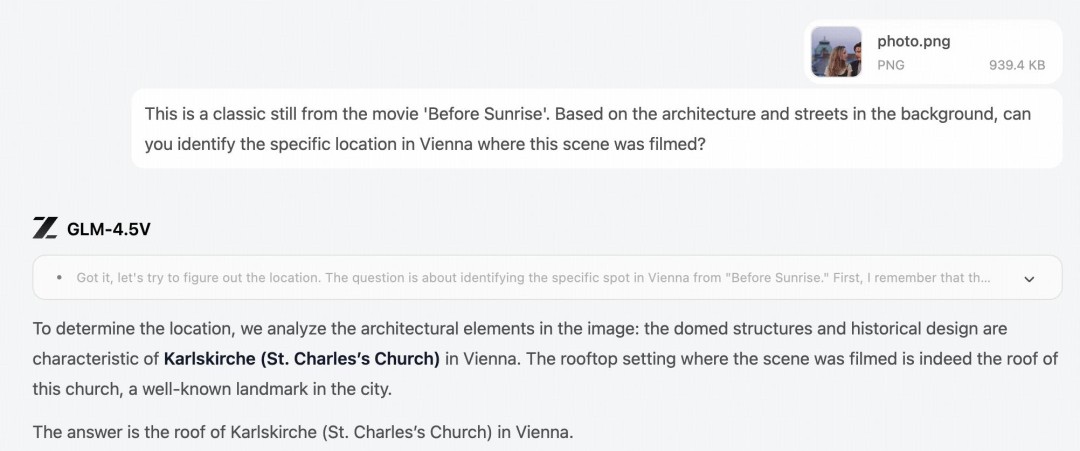
Open-world image reasoning
GLM-4.5V can infer background context from subtle visual cues without external search. Given a landscape or street photo, it can reason from vegetation, climate traces, signage, and architectural styles to estimate the shooting location and approximate coordinates.
For example, using a classic scene from Before Sunrise -“Based on the architecture and streets in the background, can you identify the specific location in Vienna where this scene was filmed?”-the model parses facade details, street furniture, and layout cues to localize the exact spot in Vienna and return coordinates and a landmark name. (See demo: https://chat.z.ai/s/39233f25-8ce5-4488-9642-e07e7c638ef6).
Image: https://www.globalnewslines.com/uploads/2025/08/f51fdc9fae815cfaf720bb07467a54db.jpg
Beyond single images, GLM-4.5V’s open-world reasoning scales in competitive settings: in a global “Geo Game,” it beat 99% of human players within 16 hours and climbed to rank 66 within seven days-clear evidence of robust real-world performance.
Complex document and chart understanding
The model reads documents visually-pages, figures, tables, and charts-rather than relying on brittle OCR pipelines. That end-to-end approach preserves structure and layout, improving accuracy for summarization, translation, information extraction, and commentary across long, mixed-media reports.
GUI agent foundation
Built-in screen understanding lets GLM-4.5V read interfaces, locate icons and controls, and combine the current visual state with user instructions to plan actions. Paired with agent runtimes, it supports end-to-end desktop automation and complex GUI agent tasks, providing a dependable visual backbone for agentic systems.
Built for Reasoning, Designed for Use
GLM-4.5V is built on the new GLM-4.5-Air text base and uses a modern VLM pipeline-vision encoder, MLP adapter, and LLM decoder-with 64K multimodal context, native image and video inputs, and enhanced spatial-temporal modeling so the system handles high-resolution and extreme-aspect-ratio content with stability.
The training stack follows a three-stage strategy: large-scale multimodal pretraining on interleaved text-vision data and long contexts; supervised fine-tuning with explicit chain-of-thought formats to strengthen causal and cross-modal reasoning; and reinforcement learning that combines verifiable rewards with human feedback to lift STEM, grounding, and agentic behaviors. A simple thinking / non-thinking switch allows builders trade depth for speed on demand, aligning the model with varied product latency targets.
Image: https://www.globalnewslines.com/uploads/2025/08/8c8146f0727d80970ed4f09b16f3b316.jpg
Media Contact
Company Name: Z.ai
Contact Person: Zixuan Li
Email: Send Email [http://www.universalpressrelease.com/?pr=zai-launches-glm45v-opensource-visionlanguage-model-sets-new-bar-for-multimodal-reasoning]
Country: Singapore
Website: https://chat.z.ai/
Legal Disclaimer: Information contained on this page is provided by an independent third-party content provider. GetNews makes no warranties or responsibility or liability for the accuracy, content, images, videos, licenses, completeness, legality, or reliability of the information contained in this article. If you are affiliated with this article or have any complaints or copyright issues related to this article and would like it to be removed, please contact [email protected]
This release was published on openPR.

{kind=link}
{kind=link}
{kind=link}
{kind=link}